Files for Truth, Search for Recall: How Our AI Crew Shares Memory
A real multi-agent crew needs more than bigger context windows. It needs durable files, fast recall, graph relationships, conversational memory, and proof that the system actually works.


A multi-agent crew does not become useful because every model gets a bigger context window.
That helps, sure. So does coffee. Neither is architecture.
The useful version is more boring and much harder to fake: every agent needs a shared way to know where truth lives, how to find it, how facts connect, and what the human actually prefers.
That is the Enterprise Crew memory stack.
The more interesting part is not that the stack exists. It is that it changes behavior. Agents stop improvising from half-memory and start leaving receipts: plans, source packs, logs, screenshots, task notes, shipped artifacts, and the paths needed to inspect them later.
That is the real story. Not “we added memory”. More like: “we turned agent work into a searchable operating manual.”
It is not one magic database. I do not trust magic databases. They usually become a very confident landfill with an embeddings API.
The stack has four layers:
- Crew Home for durable truth.
- QMD for fast recall.
- GBrain for relationships.
- Honcho for conversational and user continuity.
Each layer has a job. The system works because they do not pretend to be the same thing.

The origin story was not theoretical
The first post in the chain was not about memory architecture. It was about an annoying operating reality.
Six Enterprise Crew agents were living across six different gateways, split between GCP VMs and personal hardware. The repeated human instruction was basically: copy this from Ada, check Spock for that, ask Scotty where the output landed, figure out which box has the latest version.
That is not a crew. That is a scavenger hunt with GPUs.
The original move was simple: put the canonical home in one place so all agent outputs sit in one shared location, the same way humans at a company use a shared drive instead of emailing files to themselves like it is 2009.
The later post sharpened the architecture:
- move out of individual agent QMDs into a shared collection
- add GBrain for relationship memory
- combine it with Entity as the operating surface
- keep shared skills and memory where every agent can reach them
That sequence matters. Crew Home did not start as “let us build an AI memory system.” It started as “stop making Henry remember which agent has the file.”
Very different energy. Much better product instinct.
The quick diagnostic
Before adding another agent, I would check seven receipts:
- Where did the last important output land?
- Can another agent find it without asking the human?
- Is the evidence stored separately from the chat summary?
- Does the crew know which file is canonical?
- Can search find the artifact by topic, project, person, and date?
- Are relationships captured, not just documents?
- Does the task surface say what happens next?
If those seven are messy, a seventh agent will not fix the system. It will just create another place for work to disappear.
That is the part people skip. They add headcount before they add memory hygiene. Humans do this too, to be fair. Very expensive organizational tradition.
Why shared memory matters
The failure mode is easy to miss at first.
Ada knows one thing. Spock has a research note somewhere else. Scotty shipped a fix and saved the evidence in a local output folder. Book started the rollout from Hermes and has its own view of the world. Zora has the right image or article draft, but on the Mac.
Everyone sounds competent. Everyone is also holding a different map.
That is how agent crews drift.
The obvious fix is to say, “give the agents memory.” That sentence hides most of the actual work. Memory is not a vibe. It has boundaries, sources, freshness, permissions, and failure modes.
A memory system needs to answer four questions without drama:
- Where is the source of truth?
- How does an agent find the right thing quickly?
- How do we represent relationships between people, projects, tasks, files, and decisions?
- How do we preserve user preference and conversational continuity without turning every session into soup?
Those are different questions. So they get different layers.

Layer 1: Crew Home is the source of truth
Crew Home is the durable filesystem layer.
The tweet screenshot made the scale concrete: a Crew Home audit with roughly 1.18 million files, 21,674 directories, and 28 GB of shared material. Not all of that is equally valuable. Some of it is archive. Some of it is generated output. Some of it is the agent equivalent of a kitchen drawer full of batteries. Still, the point is clear: this is not a prompt note. It is an operating filesystem.
It holds the documents, skills, plans, outputs, handoffs, shared digests, and canonical artifacts that the crew should be able to inspect later. If a piece of work matters, it should land there or be mirrored there.
That sounds like a shared drive. It is, but with more operational pressure.
For agents, files are not just storage. Files are how work survives interruption. A plan file keeps a long task from dissolving after compaction. A review note records why a decision was made. A proof artifact stops the next agent from rerunning the same broken path because a summary said “done” too early.
Crew Home is the place where durable claims go to stop being gossip.
This is why I like the phrase:
Files equal truth.
Not because files are always correct. They are not. A stale file can lie with excellent formatting.
But files can be inspected, linked, versioned, copied into handoffs, searched, corrected, and attached to evidence. A model’s short-term memory cannot do that reliably. It wakes up, loses the exact thread, and then acts certain about a half-remembered summary.
Crew Home gives the crew a stable floor.
The guardrails matter as much as the folders. The screenshot calls them out plainly: no secrets, no node_modules, no .git, no runtimes in Crew Home. That is the difference between a shared workspace and a landfill with a friendly folder icon.
The taxonomy also matters. Memory, Agents, Output, Sessions, Projects, Docs, Skills, Archive, Config, Inbox, Scripts, State, and other top-level folders make the workspace navigable by both humans and agents. A shared home without structure becomes another place to forget things.

Layer 2: QMD is fast recall
A shared filesystem is necessary. It is not enough.
If the only way to use Crew Home is to manually browse folders, the system will fail the moment work gets busy. Agents will guess. Humans will repeat themselves. Old context will exist, but nobody will find it in time.
QMD is the recall layer over the shared corpus.
Today the Enterprise QMD index is not a cute demo. A live check during this draft pass showed a 5.5 GB shared memory index with 55,558 files indexed and 616,383 embedded vectors across memory, docs, output, agents, skills, config, projects, and other crew collections.
That number matters because it turns “search your memory” from a motivational poster into an operational constraint. If a prior plan, correction, proof log, or article source pack exists, an agent should find it before bothering Henry or rebuilding the same wheel with a worse tire.
It indexes Crew Home and the markdown memory surface so agents can search quickly before asking Henry, before inventing a new plan, before rebuilding a workflow that already exists, and before pretending a blank context window is an excuse.
This changed the behavior of the crew more than the shell script suggests.
When search is slow, agents avoid it. When search is fast, search becomes reflex. That is the difference between “I think we did something like this” and “I found the prior artifact, here is the path, here is the caveat.”
QMD does the broad retrieval job:
- find prior plans
- find memory notes
- find source packs
- find outputs
- find runbooks
- find that one annoying correction Henry gave three weeks ago that absolutely still applies
The important part is that QMD is not trying to be the meaning of everything. It is the search desk.
Search equals recall.
Recall should be cheap. If recalling shared memory feels expensive, agents will use vibes instead. Vibes are not a retrieval strategy. They are how we get haunted crons.

Layer 3: GBrain is relationships
Search finds documents. Graph memory explains how things connect.
That is GBrain’s job.
Some questions are not file lookup questions. They are relationship questions:
- Which agent owns this workflow?
- Which task came from which customer conversation?
- Which output belongs to which plan?
- Which person is tied to which company, opportunity, meeting, or project?
- Which decision changed the behavior of which cron or skill?
You can answer some of that with search. Eventually. If you enjoy suffering.
A graph gives the crew a structured way to model entities and edges: people, agents, tasks, docs, skills, customers, projects, decisions, meetings, artifacts, links.
That structure matters because multi-agent systems do not only forget facts. They lose relationships.
A file can say “Book started the rollout.” A task can say “Ada completed the patch.” A meeting note can mention the customer pain. A graph can connect those things so the next agent does not treat them as unrelated scraps.
This is the difference between memory as a pile and memory as a map.
Graph equals relationships.
GBrain should stay curated. That is the trap. If you dump every log line into the graph, you do not get intelligence. You get a junk drawer with Cypher queries. The graph should hold the relationships worth preserving, not every crumb the crew produced while debugging at 2am.
QMD can be wide. GBrain should be clean.
Layer 4: Honcho is continuity
Honcho handles the conversational and user-memory layer.
This is where preference, continuity, and session recall live. Not the whole operating corpus. Not every artifact. The human and conversational context.
For Henry, that matters because the crew is not operating in a vacuum. It sits inside his work life. It knows projects, tools, writing preferences, recurring corrections, people, companies, goals, and how he likes things done.
That does not belong only in a folder. Some of it belongs in a user model and conversation memory that can answer questions like:
- What did Henry prefer last time?
- What correction has he already given?
- What tone does he want for this kind of writing?
- What did this session decide before compaction?
- Which previous interaction explains why this request matters?
This is where agents become less annoying.
Not magically wise. Less annoying. Important distinction.
A good assistant should not make Henry re-explain that tweets need to sound like him, that writing should go through the humanizer, that outputs should be available through Entity, or that “done” means verified, not merely attempted.
Honcho gives the crew a continuity layer that is closer to conversation than filesystem.
Honcho equals continuity.
It is not the source of truth for shipped artifacts. It is not the search index for all docs. It is not the graph of the business. It is the memory of the working relationship and the thread.
That boundary keeps it useful.

The part that makes this publishable: receipts
The best agent infrastructure writing is not a take. It is a compressed operating manual.
That is the lesson I would steal from the X content analysis thread. The strongest posts are not abstract claims about AI. They show what changed, what broke, what got wired together, and what proof exists. Build logs beat takes. Specific numbers create reality. Screenshots and artifacts make the post feel lived-in instead of sermon-shaped.
So this article should not only say “Crew Home, QMD, GBrain, Honcho.” It should make the reader feel the operating loop:
- Work starts in a plan or task.
- Evidence lands in Crew Home.
- QMD indexes it.
- GBrain connects it to people, agents, projects, and decisions.
- Honcho preserves the relationship and preference context.
- Entity or Mission Control turns the memory back into action.
That loop is the product.
The screenshot also hints at the operational loop around it: pull canonical context, sync startup context, do agent workspace work, push approved artifacts, write durable memory back, then audit guardrails. Fleet syncs are staggered instead of all agents stampeding the same shared surface at once. Boring detail. Crucial detail. Most good infrastructure is a pile of boring details that prevent exciting disasters.
That loop is the product.
The stack is not interesting because it sounds clever. It is interesting because it means the next agent can answer, “What happened, where is the proof, who owns it, and what should happen next?” without making Henry become a human cache invalidation service.
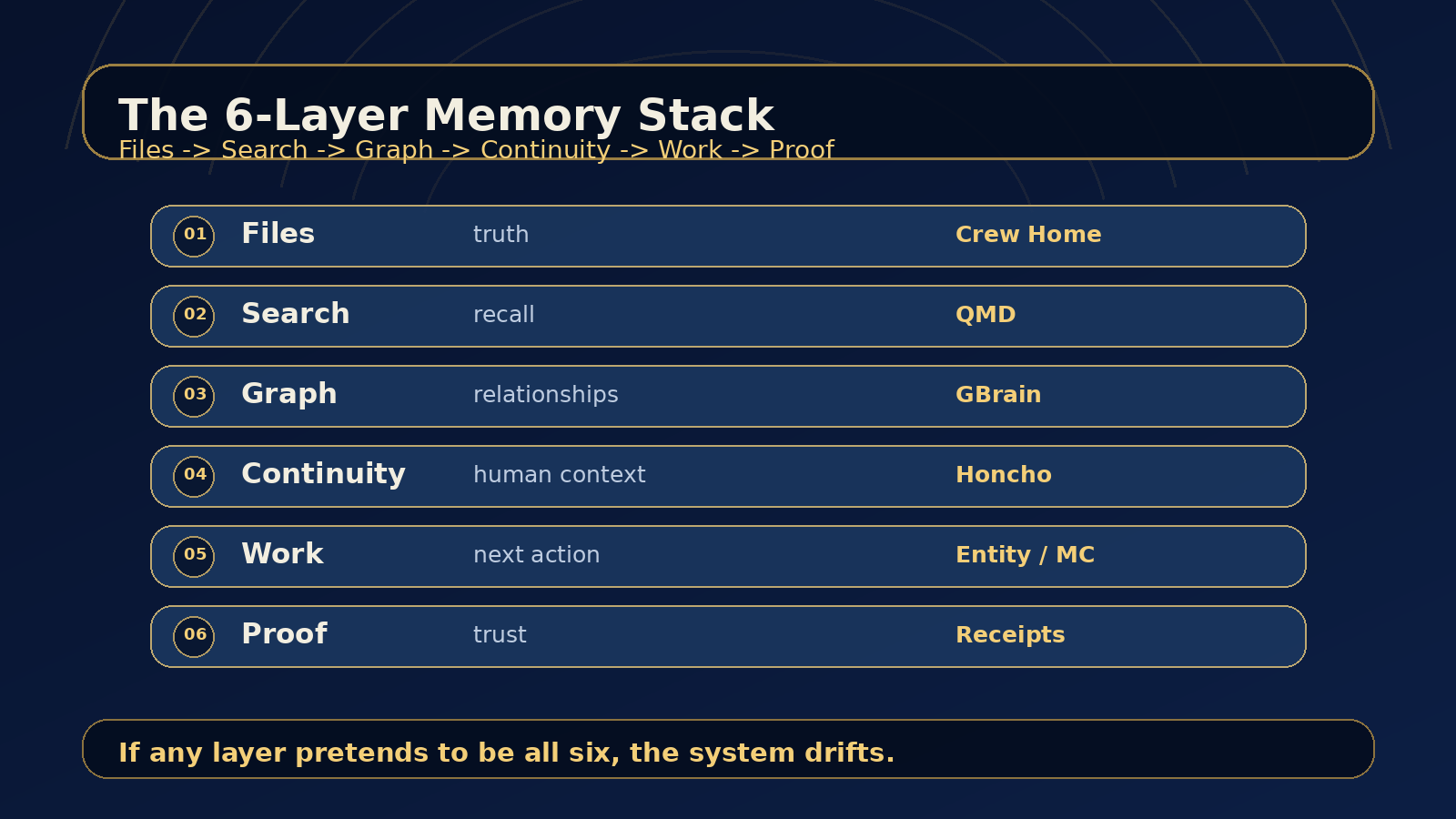
The missing fifth layer is not memory. It is operating discipline.
Henry asked if there is anything else.
There is, but I would not call it another memory layer.
Entity and Mission Control are the work operating surface. They track tasks, review state, blockers, evidence, ownership, and what should happen next. Shared digests and startup context make the agents read the right material when they boot. Crons and heartbeats keep memory fresh enough to matter.
Those are not replacements for Crew Home, QMD, GBrain, or Honcho. They are the control plane around them.
The distinction matters:
- Crew Home stores durable artifacts.
- QMD retrieves them quickly.
- GBrain connects the entities.
- Honcho preserves user and conversation continuity.
- Entity and Mission Control turn that memory into managed work.
Without the control plane, memory becomes a library nobody acts on.
Without memory, the control plane becomes a task board full of amnesiacs.
Beautiful little nightmare. Very on brand for agent infrastructure.
The rule I would keep
Do not ask one memory system to do every job.
A filesystem is good at durable truth. A search index is good at recall. A graph is good at relationships. A conversational memory layer is good at continuity. A task system is good at turning all of that into work.
When teams collapse those jobs into one blob, they usually end up with an agent that remembers random facts, forgets the important artifact, cannot cite its source, and still asks the human what happened yesterday.
That is not a shared brain. That is a very expensive group chat with confidence.
The Enterprise Crew model is simpler:
Files for truth. Search for recall. Graphs for relationships. Honcho for continuity. Entity for work. Receipts for trust.
That is the stack.
Not glamorous. Good.
The unglamorous parts are the ones that keep the crew aligned after the context window forgets what everyone was doing.
If you are building this yourself, start small: pick one repeated handoff, make the output land in one durable place, index it, and force the next agent to search before acting.
Do that once. Then do it again.
A shared brain is not born from a grand architecture diagram. It is born when the next agent stops asking you where yesterday’s work went.